In a growing body of literature, researchers leverage the occurrence of unexpected events to estimate the causal effects of events on public opinion and behaviours. Specifically, the combination of survey data collected serendipitously around the time of the unexpected event with a quasi-experimental research design makes it possible to draw inferences on the impact of the event(s) in question. This literature goes by the name of the ‘unexpected events during survey design’ literature (or, here, ‘unexpected events’ for short).
However, as is usually the case in the social sciences, we are not dealing with a ‘perfect’ experiment (or even a natural experiment, despite what some researchers call it – including myself) and, for that reason, there are still important challenges to address if our goal is to make robust causal inferences. Muñoz et al. (2020), in a seminal piece, discusses several assumptions we make when using the design and potential checks to empirically assess the validity of these assumptions (see Table 1 in the paper for a great overview).
One such example of an assumption is that the event itself does not matter for the likelihood to participate in a survey. In one extreme example, Jakiela and Ozier (2019) observed that the event of interest (a post-election crisis) halted surveying for more than two months. If anything, the more salient an event is, the more we should be concerned about the event itself shaping the composition of the sample before and after an event (and the extent to which these two groups are comparable). While I see more studies explicitly discussing these assumptions, I also encounter significant limitations in the literature when it comes to making robust causal inferences.
In a recent study, Frese (2024) demonstrates a publication bias toward marginally significant findings and a large file drawer of non-significant findings in the unexpected events literature. That is, based on the effects in the literature, we should expect a lot of unpublished studies out there. While I find the conclusion of this paper sensible, I am not convinced that this is necessarily a ‘file drawer’ issue, but rather symptomatic of the fact that researchers tend to focus more on certain types of events (and less so on events where there is little to no reason to expect any effects).
More specifically, there are several degrees of freedom when sampling and selecting potentially relevant unexpected events and characteristics. If you have to focus on event A or event B, you are more likely to focus on event A if this event got more attention by the media than event B. As we do not have a population of relevant unexpected events, we do not have a relevant baseline to assess the representativeness of events (and any potential file drawer).
Once we focus on a particular event, however, there is still a lot of freedom in how we want to go about setting up the study. For example, researchers have substantial freedom in their choice of covariates and can reverse engineer convincing, yet misleading, balance tests. Dreber et al. (2024), for example, suggest that papers in top economics journals selectively report placebo tests. That is, studies are more likely to report only the tests that strengthen the research design and findings. I believe this is also very much likely to be the case in the literature on unexpected events. Notably, an important limitation of the ‘unexpected’ feature is the limited focus on preregistering the analysis of such studies.
Furthermore, not all variables available to researchers might be meaningful covariates (see Wysocki et al. 2022 for a great introduction to statistical controls and causality). Research shows that more than 30% of the articles in the American Journal of Political Science suffer from ‘control-variable-induced increases in estimated effect sizes’ (cf. Lenz and Sahn 2021), and I would not be surprised if more than 30% of the studies in the ‘unexpected events’ literature suffer from such a limitation. I have seen examples of how the inclusion of covariates in the ‘unexpected events’ studies increases the effect sizes (and in a few cases how it goes from statistically insignificant to statistically significant).
There is a relevant distinction between predetermined covariates and placebo covariates (cf. Cattaneo et al. 2015). Predetermined covariates are determined before treatment is assigned, e.g., gender and education, whereas placebo covariates are theoretically expected not to be affected by the treatment, e.g., unrelated attitudinal questions (such as ideology). However, I am not convinced that ideology and other ‘placebo covariates’ are good covariates to include in a balance test (or even worse, as a covariate in a regression model). But that is, nevertheless, what we often see in these studies.
My primary concern with these studies today is more about the assumption that these events are in fact unexpected. I am not convinced all the events studied in this literature are truly unexpected. On the contrary, I have seen several studies over the years that rely on events that are very much expected, such as annually recurring events. In 2020, I wrote a blog post about one of these studies, exploring the causal effect of July 4th.
As a next step, I decided to look into the various studies I have identified over the years using this particular research design and causal identification strategy. In particular, I am interested in what events are being studied and whether they are unexpected or fully/partially expected. I have now identified more than 200 studies (206 to be exact) using ‘unexpected’ events to estimate causal effects with survey data. In comparison, 43 of the studies are included in the review by Muñoz et al. (2020) and 64 of the studies are included in the review by Frese (2024).
For each study, I put the event of interest into one of three categories in terms of whether it was unexpected or not: fully unexpected, partially unexpected, and not unexpected. The partially unexpected category is when there can be some ambiguity with regards to whether the event of interest was unexpected or not.
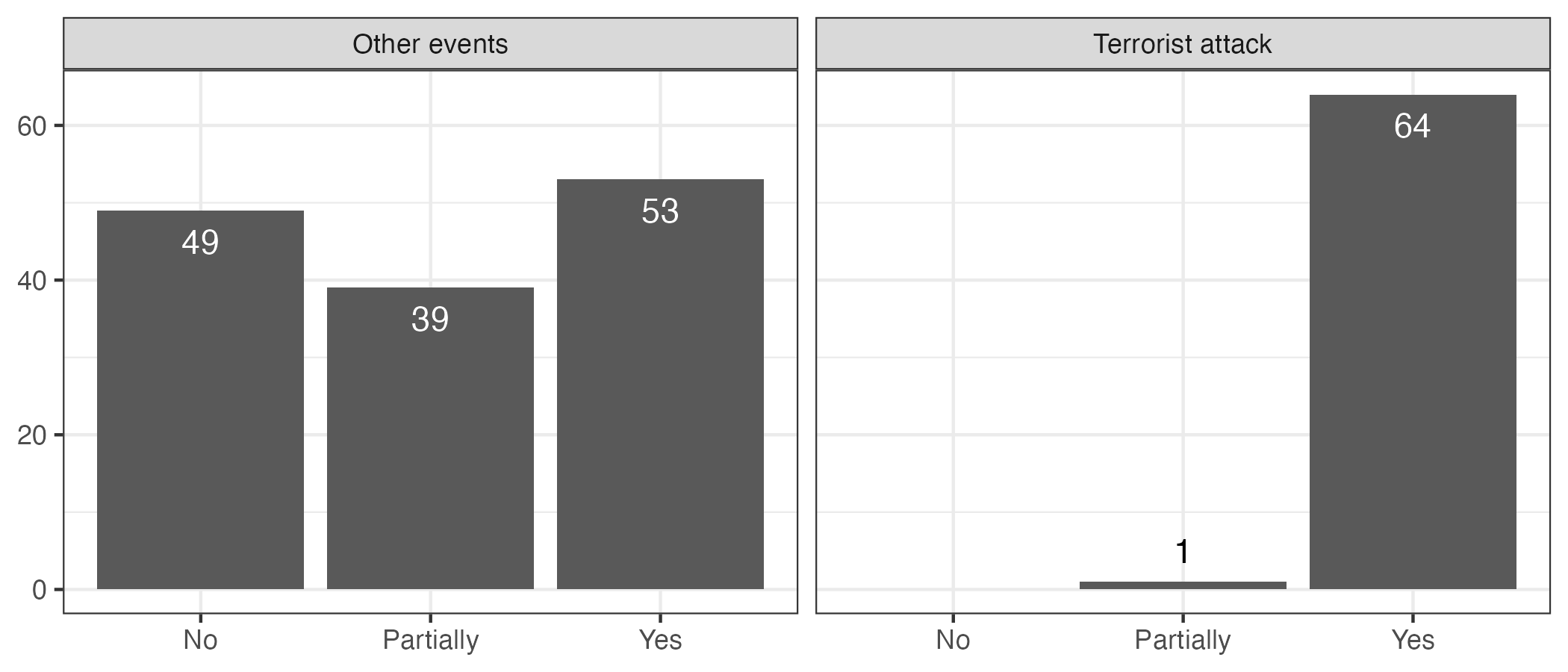
A lot of these studies deal with terrorist attacks (N = 65), and I coded 64 of them as fully unexpected. This is despite what we can call ‘event confounding’, i.e., events are more likely to occur because of other events, and thus might not be fully unexpected. For example, terrorist attacks are more likely to take place close to elections (Newman 2013, Bali and Park 2014). Similarly, political scandals are more likely to take place near elections (Garz and Sörensen 2021). Accordingly, even while specific terrorist attacks and other events might be unexpected, their timing may still correlate with predictable patterns.
The one study within the domain of terrorism I coded as partially unexpected is Bonilla and Grimmer (2013), as they do not focus directly on terrorist attacks but rather government terror alerts. However, overall, it is fair to say that terrorist attacks are the types of events that are well-suited for these types of research designs where you want to estimate the causal effect(s) of an ‘unexpected’ event.
When we consider other types of events, we see a lot more events that are not unexpected or only partially unexpected. The figure below shows whether the events being studied were unexpected or not (i.e., ‘Yes’ denotes that an event was indeed unexpected). 88 studies focus on events that are not unexpected or are only partially unexpected. In contrast, 53 studies examine events that are unexpected.
Let us take a few examples. Several studies are interested in looking at how people respond to an election or referendum, but an election or referendum is by no means an unexpected event. On the contrary, they are advertised well in advance (at least several weeks before the election). Some of the studies of interest here are Nellis (2023) on election cycles and global religious intolerance, Singh and Thornton (2024) and Hernández et al. (2021) on the salience of elections and affective polarization.
It might be that the outcome of an election is unexpected for a majority of the people, e.g., the US presidential election in 2016, but the election itself is not an unexpected event. For that reason, we cannot assume that people interviewed before an election will answer a survey prior to an unexpected event or that people interviewed after an election will answer a survey after an unexpected event. Furthermore, there are examples where I simply disagree that an election outcome in question was unexpected (see, e.g., my post on Donald Trump’s 2020 electoral defeat).
The list of ‘unexpected’ events being studied that are not unexpected is long, e.g., climate protests (Brehm and Gruhl 2024), Ramadan (Colussi et al. 2021, Grewal and Hamid 2024), Holocaust Memorial Day (Shelef and vanderWilden 2024), soccer wins (Lago and Lago-Peñas 2021), International Women’s Day (Jiménez-Sánchez et al. 2022), and the European Song Contest (Coupe and Chaban 2019). In fact, by my count, 49 of the studies in my review do not study unexpected events at all.
In fairness, a lot of these studies do not explicitly talk about unexpected events and/or causal inference. Furthermore, several of these studies are aware of methodological limitations of the research design and do not use concepts related to experimental research when drawing inferences. That being said, I would like to see the literature – in general – take these limitations into account and (re)consider whether the events being studied are indeed unexpected.
Much research remains to be done on unexpected events. For example, how unexpected is an event? Currently, the studies simply say that an event in question is unexpected, but how unexpected is it? One possibility could be to rely on a measure of “surprisal” (see, e.g., Succar et al. 2023 for an interesting example in the context of school shootings). One possibility is to have an ‘unexpected event index’, where 0 is when an event is completely expected, and 100 is when an event is fully unexpected. 4th of July is predictable and closer to 0 on an ‘unexpected event index’, whereas a terrorist attack is closer to 100.
Next, how should we consider the relationship between the salience of an event and how unexpected it is? In a lot of these studies you will see salience being used as a measure of how unexpected an event was. The idea is that if there is no salience of the event just before the event took place, we can assume that it was unexpected. There is no doubt that salience is relevant, and something to consider when we study political events (see, e.g., Oswald 2024 on the relevance of salience data from Google Trends and Wikipedia page views in conflict forecasting).
I have two particular issues with using changes in salience as a continuous measure of how unexpected an event is. First, salience data is often standardised, making it difficult to see whether there actually was a significant change or not. For example, if we study the impact of a political scandal and look at search trends of a specific politician, a change from ~0 to ~100 could simply indicate that – in the time period of interest – a few more people searched for information about that politician now than before, but not necessarily that the event was salient compared to others.
Second, the salience of an event can even say something about how expected an event is. The salience of Independence Day in the United States is much higher around July 4th every year. The salience of the presidential election in the United States is higher every four years. These patterns simply confirm that an event is to be expected, and the increase in salience simply confirms that an event was not unexpected.
So a lot of events are unexpected, but are they also salient? And a lot of events are salient, but are they also unexpected? The literature should adopt an approach that maps events along two dimensions: unexpectedness and salience. Of course, we should expect some correlation between the two dimensions (as the unexpected nature of an event can make it salient), but we should at least conceptually not conflate the two.
One possibility is to consider the uncertainty related to whether an event will happen (and maybe consider the entropy of a system made up by the population of events of interest). For example, if we study a dataset with all presidential elections, we should see a pattern of stability and predictability that we would not find in a similar dataset of terrorist attacks in Western countries. We should also expect that the less frequently an event occurs locally compared to globally, the more unexpected it becomes. And the greater the variation in the interval between events, the more unexpected. That is, the (local) frequency of events and the interval between these events can provide useful insights into how unexpected an event is and the implications for drawing causal inferences when linked to individual-level survey data.
We should also keep in mind that there is a difference between the probability of an event happening and the perceived probability of an event happening. We can even consider situations where events not taking place will be unexpected. As the most extreme scenario, if I am 100% certain something will happen, but it did not happen, it is still an unexpected event (but an unexpected non-event). Here we can also consider hypothetical events, such as news about events that could have happened (e.g., foiled plots by terrorists as studied by Nesser 2023).
This underscores the challenge of identifying the population of potentially unexpected events. In addition to the fact that studies often rely on the same event (a topic I explored in a post last year), there seems to be little interest in the literature in actually understanding the universe of unexpected events that researchers are now leveraging to identify causal effects.
The studies I have looked at care little about these questions, and my concern is that the literature is primarily going to be populated by a series of individual studies studying unique events that, in some cases, are unexpected, but in other cases are expected but salient.
In sum, in the study of unexpected events to make causal inferences, I believe that a lot of these events are not unexpected, and in some cases may be conflated with salient events, and future research should devote more attention to these challenges rather than merely studying the causal effects of yet another potentially unexpected event.