In 2017, I made a dataset with political datasets. Over the years, when I have found new datasets that might be relevant to political scientists, I have added them to the dataset and overview on GitHub. In 2017, the dataset consisted of ~150 datasets. Now it contains more than 500 datasets.
The datasets cover various topics and domains. While some datasets could easily fit within multiple categories, I provide only one category to each dataset. In the figure below I show the different categories that I have used to categorise the various datasets.
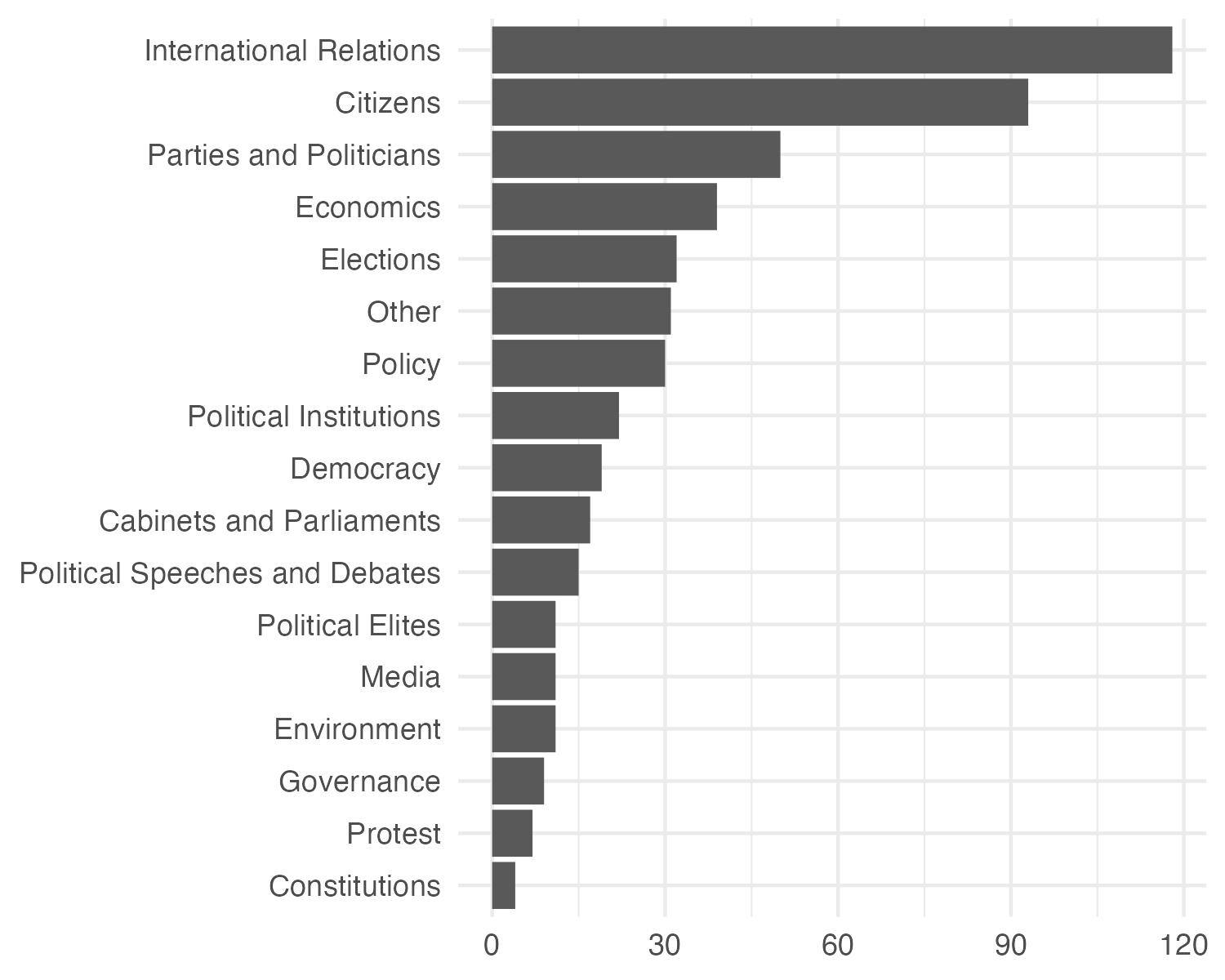
A lot of the datasets are related to international relations (especially data on conflicts) and citizens (especially individual-level survey data). However, it is my impression that the dataset now covers most of the domains of interest for quantitative political scientists.
I should note that I have not added all entries to the overview myself (see here for an overview of contributors). One of the best resources I use to find new datasets is the newsletter Data Is Plural. I have recommended the newsletter before, and if you do not already subscribe, do sign up.
An important question that I often have to deal with is whether a dataset is a political dataset. What some might say is a dataset of relevance for political scientists, others might say is not relevant at all. For example, some researchers could say that the Australian Shark Incident Database might be a relevant resource if we are to study democratic accountability, but I decided not to include such datasets.
It is great to see that the resource is used by students and researchers alike. A recent good example is in the paper by Mongrain (2022) on social networks and citizens’ forecasting ability. Here, the resource is used to identify relevant survey data that can be used to test the hypotheses of interest: “First, I searched codebooks and questionnaires from every election survey available on national and regional election studies’ websites for relevant items (some of these resources were found through online dataset repositories such as Erik Gahner’s PolData and odesi).”
The dataset is still work in progress but if you are aware of any datasets that I have missed, please do let me know and I will add them. I started some years ago to add information on when exactly an entry was added or revised, and I plan to continue to update the individual entries in the future. Similarly, I am working on ways to make it easier to identify event data, geolocated data, text-as-data data, the unit of analysis, etc.