Meningsmålinger er desværre ikke altid så præcise som journalister gør dem til. Står Enhedslisten til at få 14,9 pct. af stemmerne i en meningsmåling, er det som bekendt et kvalificeret gæt. Når medierne angiver partiernes procentvise andel af stemmerne helt ned til én decimial, sælger det blot en illusion om præcision.
Så længe vi ikke spørger alle vælgere om, hvilket parti de vil stemme på, skal vi altid forholde os til en grad af usikkerhed. De eneste eksempler vi har på meningsmålinger med en statistisk usikkerhed på 0, er valgresultaterne fra valg til Folketinget, kommunerne, regionerne og Europa-Parlamentet (altså når vi rent faktisk spørger hele populationen).
Den statistiske usikkerhed gør, at partiernes opbakning kan variere fra meningsmåling til meningsmåling, uden så meget som at én vælger har skiftet parti. Det er derfor helt naturligt, når de enkelte analyseinstitutter gennemfører meningsmålinger, at de kommer frem til lidt forskellige resultater. Dette illustreres bedst i valgkampe, hvor flere institutter gennemfører meningsmålinger dagligt. Følgende viser Socialdemokraternes opbakning i løbet af valgkampen i 2011 (kilde):
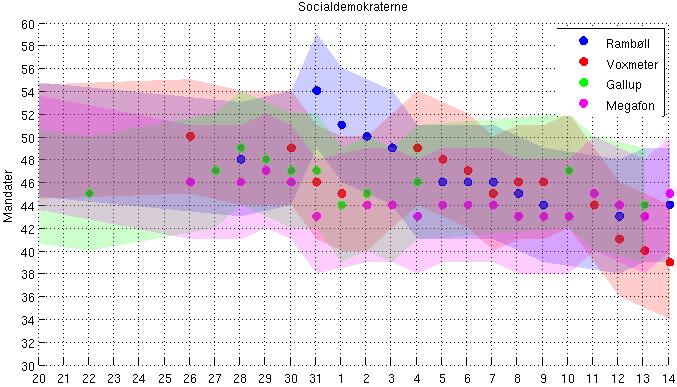
Hvilke meningsmålinger der rammer helt plet, kan vi i sagens natur ikke vide. Vi kan dog med al rimelighed betvivle, at én meningsmåling der ligger langt fra hvad andre meningsmålinger viser, giver et retvisende billede af virkeligheden. Det er her vi oplever noget paradoksalt ift. mediernes interesse for meningsmålinger: Jo mindre sandsynligt det er en meningsmåling rammer plet, desto mere opmærksomhed vil den få.
Når meningsmålingerne viser det samme, er det med en begrænset nyhedsværdi. Journalister er ikke interesserede i at skrive om, at verden er den samme i dag som i går. Viser en meningsmåling omvendt noget ekstremt (eller blot en eller anden form for forandring), får det straks en langt højere interesse blandt journalister, læsere, kommentatorer m.v.
Derfor bør man tillægge enkelte meningsmålinger mindre vægt, og se mere på hvilket billede de forskellige meningsmålinger sammenlagt tegner. Da Nate Silver påbegyndte arbejdet med bloggen FiveThirtyEight, var det med udgangspunkt i en simpel fremgangsmåde: Tag gennemsnittet af forskellige meningsmålinger og vej dem efter analyseinstitutternes tidligere præcision.
I en dansk kontekst har vi Berlingske Barometer og de kvalitetsvægtede gennemsnit fra Altinget.dk, som valgforsker og professor ved Aarhus Universitet Søren Risbjerg Thomsen udarbejder hver måned. Disse vægtede gennemsnit giver et mere retvisende billede af hvordan partierne ligger. Der kan selvfølgelig godt være en meningsmåling der er mere korrekt end det vægtede gennemsnit, når andre meningsmålinger viser noget der ikke ligger lige så tæt på. Vi kan dog ikke vide hvilken meningsmåling der eventuelt rammer mest præcist – og de er stadig alle underlagt en grad af usikkerhed.
Den store fordel ved de vægtede gennemsnit er dermed, at de reducerer den usikkerhed vi opererer med. Usikkerheden varierer alt efter partiets størrelse, hvor usikkerheden er større desto tættere et parti ligger på 50 pct. af stemmerne. Grunden til dette ligger i den måde man beregner usikkerheden for hvert parti:

Standardfejlen er angivet ved se, og som det kan ses, vil den falde i takt med at vi spørger flere respondenter (jo større n, desto mindre se). Partiets andel er angivet ved p. Hvis en meningsmåling har spurgt 1.000 vælgere, vil det give en standardfejl på 0,0158 for et parti der får en andel på 0,5 af stemmerne, og en standardfejl på 0,0031 for et parti der står til en andel på 0,1 af stemmerne (eller 0,9). Har du lyst til at beregne usikkerheden for et partis andel, kan det gøres her. Aftenens udgave af Detektor havde desuden et fint indslag omkring forholdet mellem stikprøvestørrelse og usikkerhed i meningsmålinger.
Hvis vi tager et partis andel ± en standardfejl, vil vi få et 68 pct. konfidensinterval for partiet. De fleste meningsmålinger rapporterer dog usikkerheden i form af 95 pct. konfidensintervaller, som fås ved ± 1,96 standardfejl. Får et parti 50 pct. af stemmerne i en meningsmåling der har spurgt 1.000 tilfældigt udvalgte vælgere, giver det dermed en usikkerhed på ±3,099 med et 95 pct. konfidensinterval. Et parti der står til at få 5 pct. af stemmerne i samme meningsmåling, vil have en usikkerhed på ±1,351.
Hvad er implikationen af dette når vi diskuterer enkeltmålinger i forhold til kvalitetsvægtede gennemsnit? Tager vi en enkelt meningsmåling, vil usikkerheden som sagt være størst for de store partier, hvorved kvalitetsvægtede meningsmålinger vil have en større betydning, da forskellige meningsmålinger hver især vil ligge længere fra hinanden når det kommer til de store partier ift. de mindre (ceteris paribus og forudsat de ellers er repræsentative, forstås).
De små partier vil derfor generelt ligge tættere på det vægtede snit i en enkelt meningsmåling end de større. Dette kan vi selvfølgelig illustrere ved hjælp af empiri. Jeg har taget Søren Risbjerg Thomsens vægtede snit fra perioden 1990 til 2010 og Gallups menigsmålinger fra samme periode. Nedenstående plot viser differensen mellem Risbjergs snit og Gallup på y-aksen og partistørrelsen ([Risbjerg+Gallup]/2) på x-aksen for 2.098 partiestimatforskelle.

Jo større partiet er, desto større vil differensen være mellem det vægtede snit og enkeltmålingen. Sagt med andre ord: Jo større et parti er i en meningsmåling, desto mindre kan vi være sikre på, at én meningsmåling rammer plet. Vi har derfor brug for kvalitetsvægtede gennemsnit af meningsmålinger til at reducere den tilfældige støj. En tilfældig støj der kun bliver større, desto større et parti er. Man skal desuden bemærke, at da Gallup er inkluderet i Risbjergs snit, er forskellen angivet i plottet mindre end hvis Risbjergs snit ikke havde inkluderet meningsmålinger fra Gallup.
Vægtede meningsmålinger er alt andet lige at foretrække frem for enkeltmålinger. Når de forskellige medier formidler spændende nyheder omhandlende forandringer i meningsmålingerne, så vent og se om disse forandringer manifesterer sig i de vægtede snit. Ellers er tilfældet nok bare, at der var tale om tilfældige udsving i en enkelt måling.